Виктор Корнеев

Процессор, выполняющий каждую команду за четыре такта (выбор команды, декодирование и выбор операндов, исполнение, запись результата), в принципе, обеспечивает полезную работу только в такте «исполнение». Для увеличения столь низкой (25%) эффективности используется конвейерная организация: такты последовательно выбираемых команд совмещаются во времени так, что в каждый период одна из команд обязательно находится на этапе «исполнение». Для организации конвейера требуется дополнительная аппаратура, но выигрыш в производительности это оправдывает.
Для выполнения преобразований, задаваемых командами процессора, служит совокупность функциональных устройств (ФУ), таких как целочисленное АЛУ, АЛУ с плавающей точкой и другие. Если длительность преобразования в ФУ превышает один такт, появляется возможность осуществления другим ФУ (или тем же ФУ — при конвейерной реализации) преобразования, задаваемого следующей командой. При этом не нужно дожидаться завершения уже выполняемых преобразований, а в результате вычисления ускоряются.
Процессоры, реализующие эту возможность, называют «суперскалярными». В них каждая команда предназначена для выполнения на одном ФУ, а для загрузки нескольких ФУ требуется выбрать несколько команд. Управляемая одной командой загрузка совокупности ФУ использована в процессорах с длинным командным словом (VLIW): в команде явно прописываются операции для нескольких ФУ. Другая реализация программно управляемой загрузки ФУ — векторные команды: одна команда инициирует обработку предварительно подготовленных векторов данных, обычно размещаемых в специальных регистрах.
Уменьшение длительности такта, разработка процессоров с многотактными конвейерами (в том числе с совокупностью многотактных ФУ) потенциально обеспечивают быстродействие, пропорциональное суммарной производительности используемых ФУ. Однако простои устройств из-за невозможности загрузить их преобразованиями исполняемой программы обуславливают снижение производительности. Эти простои связаны, по крайней мере, с тремя факторами: ожидание завершения обмена с существенно более медленной памятью, выполнение команд условных переходов, зависимости между командами — по данным и используемым ресурсам (например, регистрам).
Для борьбы с простоями, связанными с медленной памятью и ограничениями ее объема, введена страничная организация. Она представляет собой способ быстрого отображения виртуальных адресов в физические посредством ассоциативных таблиц с адресами обращений к памяти (TLB) и кэш-памяти. Кроме того, используется расслоение памяти. Все это позволяет при обеспечении временной и пространственной локализации обращений к памяти создавать эффект быстрого доступа.
Для уменьшения потерь производительности из-за простоев ФУ, обусловленных определением направлений переходов в исполняемой программе, служат схемы предсказания переходов и переупорядочивания команд (выполнения в ином порядке). Последний метод позволяет ослабить влияние на время простоев ФУ истинных зависимостей между командами «чтение после записи — RAW» (вычисления должны остановиться на команде, которая будет использовать пока не полученный результат другой команды — поступившей на исполнение, но не завершенной).
Совокупность этих и ряда других приемов обеспечила повышение производительности вплоть до достижения технологических норм уровня 0,18 мкм [1]. Однако далее потребовались новые архитектурные подходы.
Объем устройств, обеспечивающих загрузку суперскалярных процессоров, достаточно велик и растет пропорционально квадрату находящихся в обработке команд. Это ведет к увеличению на кристалле доли устройств, не выполняющих обработку данных при росте количества совмещаемых команд. Суммарный объем схем управления однокристальной системы, состоящей из простых процессоров, может быть существенно меньшим, чем в микропроцессоре с суперскалярной архитектурой, при одинаковом суммарном числе функциональных устройств.
Для борьбы с простоями ФУ в процессорах предложена мультитредовая архитектура. В ее рамках процессор исполняет несколько потоков команд (тредов), совместно загружающих ФУ. В программах, выполняемых на мультиядерных кристаллах с мультитредовыми ядрами, выделяют два вида параллелизма: на уровне ядер (в них под управлением традиционных ОС осуществляются вычислительные процессы программы) и на уровне тредов (аппаратно поддерживается переключение с одного потока команд — в котором возникла ситуация, ведущая к простою ФУ, — на исполнение других тредов без вмешательства ОС).
Исходный вариант концепции мультитредовых вычислений реализует, например, компания Cray, которая сосредоточила усилия на производстве кристалла Eldorado. Развитие этого проекта должно привести к созданию суперкомпьютера с развитым программным обеспечением, чего не удалось сделать с Tera MTA и MTA-2. Последние продемонстрировали высокую эффективность в прикладных задачах, но оказались недостаточно надежными и отлаженными [2]. Процессор Eldorado создается для применения именно в суперкомпьютере, который должен иметь ту же архитектуру, которая присуща системе Red Storm (она была создана Cray для Sandia National Laboratory и выпущена в свет как Cray XT3; www.cray.com/products/xt3). Предполагается, что Eldorado заменит в вычислительных узлах AMD Opteron.
Процессор поддерживает 128 аппаратных тредов и имеет четырехвходовую кэш-память команд объемом 64 Кбайт, поделенную между тредами (по 500 байт). Процессор может располагать 4–16 Гбайт локальной памяти. Каждый тред содержит 32 универсальных регистра, целевой регистр и слово состояния, которое включает в себя и счетчик команд треда. В каждом такте процессор переключается на новый тред. В процессоре есть три функциональных блока — М, А и С. Они, соответственно, выполняют М-операций чтения-записи между памятью и регистрами, A-операций умножения-сложения, C-операций управления и сложения. Команда процессора состоит из трех полей, каждое из которых содержит операцию одного из перечисленных блоков.
На концептуальном уровне мультиядерные кристаллы с мультитредовыми ядрами были предложены IBM в рамках проекта Blue Gene [3]. Компания SUN реализовала эту концепцию, выпустив 32-тредовый кристалл Niagara [4] с восемью ядрами, которые аппаратно поддерживают по четыре треда. Каждый тред имеет собственные набор регистров, буферы команд и данных. Треды переключаются в каждом такте, причем приоритет предоставляется наименее вызываемому треду. Если выполняются команды большой длительности (обращения к памяти для чтения или записи, переходы, умножение, деление), треды становятся необслуживаемыми. Причинами остановок тредов могут быть «промахи» в кэш-памяти, прерывания и связанные с ресурсами конфликты.
Предполагается, что следующий за Niagara кристалл Rock будет иметь восемь ядер, каждое из которых является четырехтредовым SMT-процессором с одновременным выполнением тредов. В Rock также будет использована разделяемая внутрикристальная кэш-память второго уровня. Для ускорения выполнения тредов намечено задействовать предвыборку данных из памяти с помощью метода вспомогательных тредов (Helper-Threads) [5], называемого также «аппаратным поиском» (hardware-scouting) [6]. Суть его состоит в том, что при выполнении команды большой длительности тред не останавливается, а переходит в специальный поисковый режим. В нем продолжается ускоренное выполнение программы треда, определяются адреса доступа к памяти и осуществляются обращения к ней с целью предвыборки данных. Поисковый режим продолжается до устранения причины приостановки треда, после чего исполнение треда возобновляется с точки прерывания.
Утверждается, что треды в ядре Niagara переключаются без потери тактов, но разделение тредами кэш-памяти и TLB ведет к неявному увеличению времени такого переключения. Это связано с тем, что учащаются «промахи» в кэш-памяти и TLB, возникают «лишние» откачки и подкачки кэш-строк. Этот эффект проявляется в двухтредовых процессорах Intel: введение двух тредов отнюдь не удвоило их производительность (в тесте семейства SPEC среднее ускорение составляет лишь 1,2, а во всех программах набора — от 0,9 до 1,58 [7]).
Еще одна реализация мультиядерного кристалла представлена компанией ClearSpeed. Она разработала кристалл CSX600, на котором размещен восьмитредовый процессор с 96 процессорными ядрами [8]. В систему команд восьмитредового процессора входят монокоманды (выполняются им самим) и поликоманды (предназначены для исполнения в режиме SIMD всеми 96 процессорными ядрами — над собственными наборами регистров и данными блоков встроенной памяти). В кристалле развиты средства синхронизации тредов между собой и вводом-выводом с применением аппаратно реализованных семафоров. Кристалл имеет два порта, позволяющих создавать многокристальные системы. Пиковая производительность составляет 25 GFLOPS при одинарной и двойной точности. Кристалл CSX600 с SIMD-ускорителем ориентирован на массовое распараллеливание по данным, в том числе в системах обработки мультимедийных данных в режиме реального времени.
По сравнению с рассмотренными кристаллами более «рельефным» является Cell [9]. Он содержит основной двухтредовый процессор с архитектурой PowerPC (PowerPC Processing Element, PPE), блок SIMD для обработки 128-разрядных данных и восемь ускоряющих дополнительных процессоров (Synergistic Processing Element, SPE), управляемых основным процессором. Каждый SPE имеет собственную локальную память объемом 256 Кбайт. Все PPE и SPE получают доступ к основной памяти PPE через контроллер разделяемой памяти и внутреннюю объединяющую магистраль.
SPE может выполнять за такт четыре операции накопления (умножения с последующим сложением) над 32-разрядными операндами, так что восемь SPE выполняют в такте 64 операции с плавающей точкой (одинарной точности). При тактовой частоте 4 ГГц суммарная производительность достигает 256 GFLOPS. Подчеркнем, SPE может выполнять и операции с плавающей точкой двойной точности в соответствии со стандартом IEEE754, но при этом его производительность уменьшается на порядок, что при тактовой частоте 4 ГГц соответствует 25 GFLOPS.
Архитектурная особенность Cell состоит в том, что адресное пространство основного процессора PowerPC доступно для передачи блока данных из памяти основного процессора в локальную память SPE и обратно (через каналы DMA прямого доступа к памяти каждого SPE). Для программирования DMA может быть использована каждая из трех возможностей: программирование исполняемыми SPE командами, подготовка списка команд в локальной памяти SPE и выборка на исполнение списка DMA команд, внесение команд в очередь DMA другим процессором с соответствующими привилегиями.
Внутренняя объединяющая магистраль «видит» единое адресное пространство, разделяемое между PPE и всеми SPE, что позволяет легко программировать DMA каждого SPE для передачи требуемых данных. Указатель структуры данных, созданной в PPE, может быть передан в SPE для использования при программировании его DMA. В SPE задействуются команды синхронизации и почтовые ящики, аналогичные применяемым в PPE для целей межпроцессной синхронизации и взаимного исключения доступа к разделяемым ресурсам.
Внутренняя объединяющая магистраль выполнена как четыре кольцевых канала шириной по 128 разрядов. Данные передаются по кольцевому каналу через буфер каждого SPE, переходя за такт процессора между буферами соседних SPE. Отдельные буферы служат для приема данных из канала в SPE и выдачи в канал 8 байт за такт. При передаче данных в кольцевых каналах централизованно резервируются буферы. Это позволяет избежать конфликтов и сделать предсказуемым выполнение передач, что необходимо для приложений реального времени.
Память SPE находится под полным программным управлением исполняемой программы. В SPE отсутствует кэш-память, активность которой программисту сложно учитывать в процессорах с традиционной многоуровневой структурой кэш-памяти, в том числе из-за обращений к операционной системе. В Cell введена и возможность управления размещением данных в кэш-памяти PPE. Все это облегчает достижение высокой производительности, для обеспечения которой в процессорах с традиционной многоуровневой кэш-памятью требуется применение упреждающей предвыборки данных — для уменьшения простоев в ожидании данных и управления заменой строк кэш-памяти. Для достижения той же цели необходимо управлять заполнением таблицы отображения виртуальных адресов в физические, благодаря чему можно избежать долгих простоев при смене страниц [10].
Треды могут назначаться для выполнения на SPE или PPE. Процессор SPE поддерживает контекст только одного треда, который может быть как прикладным, так и системным, например тредом операционной системы.
SPE допустимо использовать как ускоритель при выполнении наиболее тяжелых в вычислительном аспекте фрагментов кода и процедур. Скажем, в случае применения библиотеки, поставляемой для специфичных вычислений, PPE обращается при выполнении программы к одному или нескольким SPE для реализации необходимых функций. Выявление фрагментов кода, предназначенного для исполнения в SPE, ложится на программиста или компилятор. Другая возможность применения SPE — создание параллельной программы, в которой PPE координирует функционирование SPE (параллельную программу также должен подготавливать программист или компилятор).
Кристалл Cell можно рассматривать как процессор с интеллектуальной памятью, участки которой посредством каналов DMA доступны для автономной обработки одновременно с функционированием основного процессора.
В работе [11] много внимания уделено уже аппаратной реализации вычислений путем настройки ПЛИС (FPGA), однородных сред и программируемых Raw микропроцессоров для выполнения требуемого алгоритма. Компания Cray производит систему CrayXD1, а Silicon Graphics — систему RASC, в которых ПЛИС с подключенной к ним памятью образуют программируемые сопроцессоры, связанные высокоскоростными магистралями с основным процессором и между собой.
Однако в архитектурном аспекте выделяется разработка компании Stretch (www.stretchinc.com) — попытка создать процессор с программно изменяемой системой команд. Stretch предлагает компилятор с языков Cи/C++, который автоматически выявляет фрагменты кода, эффективно реализуемые на ПЛИС, и создает необходимое расширение набора команд. Пользователь может редактировать этот набор по своему усмотрению, вводя в него необходимые команды. Достигаемое ускорение зависит от исполняемой программы и адекватности выбора фрагментов программы для реализации в ПЛИС, а потому его интервал достигает трех порядков.
С аппаратной реализацией вычислений идеологически и технологически связаны потоковые (data-flow) вычисления, в рамках которых данные передаются между обрабатывающими устройствами в соответствии с реализуемым алгоритмом. Современные САПР ПЛИС и СБИС воспринимают программы data-flow как описания проектируемых устройств.
Интерес к потоковым вычислениям обусловлен их адекватностью структурам вычислителей, эффективно реализуемых на СБИС. Уже при технологических нормах 0,13 мкм 64-разрядный блок операций с плавающей точкой занимает площадь менее 1мм2 и расходует около 50 пДж (пикоджоуль) энергии на одну операцию при тактовой частоте 500 МГц. В то же время передача данных на расстояние, равное длине одной из сторон кристалла 14х14 мм2, требует около 1 нДж (наноджоуль), то есть в 20 раз больше энергии [12]. На кристалле 14х14 мм2 можно разместить около 200 АЛУ с короткими связями между ними (например, со связями каждого АЛУ только с соседями по двумерной решетке). При тактовой частоте 500 МГц производительность кристалла составляет 100 GFLOPS [13].
Нельзя сказать, что эта возможность развития микроэлектроники осознана недавно. Основные положения концепции предлагаются в [14], а в [15] рассматриваются архитектура и организация функционирования потоковых систем, основанных на близкодействии. Однако сейчас технологические возможности производства СБИС сделали экономически выгодным построение именно таких систем. В качестве примеров достаточно реалистичных проектов упомянем Merrimac [13] и TRIPS [16].
Система Merrimac с потоковой архитектурой (streaming architecture) строится на базе заказного кристалла. Он реализует потоковый процессор с большим количеством (около 100) 64-разрядных АЛУ с плавающей точкой. Возможна передача через очереди FIFO операндов с выходом одних АЛУ на входы других, а также из памяти — на входы АЛУ и с выходов АЛУ — в память. Прикладная задача представляется как программа data-flow, граф потоков данных которой имеет в вершинах короткие программы-ядра (kernels). Помимо кристаллов Merrimac с подсоединенной к ним памятью в системе есть еще иерархическая коммуникационная структура. Она обеспечивает передачу данных через очереди FIFO с быстродействием не менее 1/8 пропускной способности внутри кристалла. Для достижения производительности 1 PFLOPS необходимо 8К кристаллов Merrimac [13].
В рамках другого проекта, TRIPS (Tera-op Reliable Intelligently-adaptive Processing System), также используется архитектура EDGE явного исполнения графа потока данных (Explicit Data Graph Execution). Система базируется на заказном кристалле TRIPS, содержащем два массива 4х4 64-разрядных АЛУ с плавающей точкой. Каждый массив имеет собственное управление. В TRIPS вершины графа потоков данных программы должны состоять ровно из одной команды, а не из программ-ядер (kernels), которые могут иметь сотни команд (как в Merrimac). В командах TRIPS, в отличие от традиционных систем команд, не указываются операнды: в них фигурирует только команда — потребитель результата. Команда срабатывает, когда из неизвестных ей источников поступают операнды. После выполнения она рассылает результаты соседним АЛУ или регистрам по известным ей связям.
Компилятор должен разбивать программу на гиперблоки, каждый из которых представляет собой подграф графа потоков данных программы, имеющий до 16 вершин. Компилятор отображает 16 команд каждого гиперблока на массив 4х4 АЛУ, назначая по одной команде на АЛУ. Он обеспечивает передачу данных между гиперблоками с помощью значений, сохраняемых в регистрах. Будучи загруженными в массив 4х4 АЛУ, команды гиперблока асинхронно выполняются по мере поступления операндов. Для каждого гиберблока известно, сколько результатов он вырабатывает. Специальная аппаратура массива 4х4 АЛУ отслеживает время его завершения, после чего массив 4х4 АЛУ начинает исполнять следующий гиперблок.
Упомянутые подходы не исчерпывают всего многообразия возможностей (например, есть еще и японские проекты векторных процессоров), однако общее направление заключается в создании на кристалле компактных обрабатывающих устройств и в минимизации длины связей. Особо подчеркнем, что аппаратный способ реализации вычислений, в том числе потоковых, становится таким же распространенным, как программный. В реализуемых проектах упор делается на разных моделях вычислений, аппаратной (потоковой) и мультитредовой, а также на симбиозе этих моделей в одной вычислительной установке.
Обрабатывающий блок кристалла ClearSpeed (CSX Processor Architecture Whitepaper; www.clearspeed.com) представляет собой мультитредовый матричный процессор MTAP (multi-threaded array processor).
На каждом такте восьмитредовый процессор извлекает команду, декодирует ее и направляет в исполнительные блоки mono или poly либо на контроллер ввода-вывода. Набор команд традиционен для RISC-процессоров — это трехадресные команды. Кроме того, процессор выполняет команды перехода и управляет переключением тредов. Команды выполняются над операндами mono или poly, причем некоторые из них реализуются только в каком-то одном блоке (например, команды переходов — лишь в mono).
Параллельный исполнительный блок состоит из 96 PE-ядер. Каждое ядро имеет АЛУ, набор регистров, локальную память и блок ввода-вывода. В число исполняемых включены целочисленная операция накопления MAC и операции двойной точности с плавающей точкой. Количество ядер может быть больше или меньше 96, но важно то, что они синхронно исполняют один поток команд в режиме SIMD. Данные, которые должны обрабатываться параллельно, снабжены описателем poly.
Процессор поддерживает для каждого треда его контекст. Если PE-ядра выполняют длительный ввод-вывод, то процессор должен переключиться на другой тред. При этом треды имеют приоритеты, и готовый тред с более высоким приоритетом прерывает выполнение треда с более низким. Треды синхронизируются друг с другом и контроллерами ввода-вывода через аппаратные семафоры.
Семафоры представляют собой специальные регистры, значения которых увеличиваются или уменьшаются с помощью неделимых атомарных команд — соответственно, signal и wait. Если wait выполняется над семафором с нулевым значением, то выполнение команды приостанавливается до тех пор, пока не будет исполнена команда signal над этим семафором в другом треде или устройстве. Операции над семафорами способны выполнять и аппаратные блоки, например контроллеры ввода-вывода.
Каждое ядро PE может выполнять или не выполнять команды в зависимости от значения разрешающих битов. Если все эти биты составляют «1», то команда выполняется. Если же хотя бы один из таких битов равен «0», большинство команд не выполняются (за исключением, например, команд изменения состояния разрешающих битов). Регистр разрешающих битов трактуется как стек: биты заходят в него через вершину.
Условное выполнение команд в PE поддерживается poly-командами перехода: if, else, endif и др. Они управляют значениями битов разрешения. Например, при выполнении команды if сравнения двух операндов во всех PE происходит следующее: в тех PE, где есть совпадение, в вершину стека будет помещена «1», а в тех, где обнаружено несовпадение, в вершину стека помещается «0». Соответственно, эти PE будут или не будут выполнять последующие команды — вплоть до команды endif, которая «вытолкнет» из стека значение, занесенное командой if. Стек имеет фиксированный размер, поэтому необходимо следить за его переполнением.
Команды чтения и записи из локальной памяти PE в регистры также могут выполняться или нет в зависимости от значения разрешающего бита. Для безусловного выполнения обмена между памятью и регистрами введены специальные команды forced load и forced store.
Канал ввода-вывода PE включает в себя контроллер и один или несколько каналов прямого доступа. Контроллер интерпретирует команды ввода-вывода и взаимодействует с тредами посредством семафоров. Обмен между локальной памятью PE и внешними устройствами выполняется путем программируемого ввода-вывода или с использованием каналов прямого доступа в локальную память. Каждый процессор может читать свою часть данных или выполнять общее чтение — с «нарезкой» одинаковых блоков для каждого процессора.
PE способны осуществлять обмен с «соседями» справа и слева. На каждом такте PE может выполнить передачу из своего регистра в регистр правого или левого «соседа» и получить одновременно справа и слева данные в свои регистры. Используются команды сдвига вправо и влево, а также передачи «соседу». Если PE имеет бит разрешения «0», то соседний процессор не может изменить состояние его регистров.
Интерфейс внешней памяти имеет 72 бита для контроля и коррекции данных (Error Checking and Correction — ECC). Используется память 64-бит DDR2 SDRAM объемом до 4 Гбайт. Процессор имеет 64-разрядное адресное пространство, которое отображается в 48-разрядное физическое. Порты CCBR0 и CCBR1 предназначены для образования мультикристальных систем, а также могут служить для подключения ПЛИС.
Внутрикристальная магистраль позволяет одновременно выполнять несколько обменов, например обеспечивает доступ процессора к внутренней памяти eSRAM. Кроме того, она дает возможность вести передачу данных из внешней памяти на порты CCBR0 или CCBR1 с использованием канала DMA.
Кристалл производится по технологии 0,13 мкм. Тактовая частота — 250 МГц, мощность — 10 Вт.
Кристалл компании Stretch представляет собой реконфигурируемый процессор, в состав которого входит блок программируемой логики. Компания предлагает компилятор с языков Cи/C++, который автоматически создает для каждой программы, во-первых, битовую последовательность с целью программирования встроенной ПЛИС на исполнение вновь введенных команд, а во-вторых, собственно компилированную программу, включающую в себя эти новые команды наряду с командами архитектуры MIPS.
Stretch выпускает семейство процессоров S5, основу которых составляет ядро Xtensa — лицензированный продукт Tensilica (www.BDTI.com). Отличием Xtensa от других 32-разрядных ядер является то, что смесь 16-разрядных и 24-разрядных команд может изменяться путем перепрограммирования кода ядра на языке TIE (Tensilica Instruction Extension), похожем на Verilog. Ядро с вновь введенными командами изготавливается как специализированная интегральная схема (ASIC).
Stretch разработала собственный блок расширения набора команд Stretch Instruction Set Extension Fabric (ISEF). Для связи с программируемой логикой используется регистровый файл, состоящий из 32 регистров по 128 разрядов. Файл 128-разрядных регистров имеет по три входа и выхода. Он способен выдавать на вход ПЛИС блока ISEF в каждом такте три 128-разрядных операнда, а получать два 128-разрядных значения, вырабатываемых блоком ISEF, и 128-разрядное значение из памяти.
Встроенная память имеет такие характеристики: 32 Kбайт RAM память данных, 32 Kбайт кэш-память данных, 32 Kбайт кэш-память команд; тактовая частота ядра Xtensa — 300 МГц, порт внешней памяти SDRAM DDR400 имеет ширину 64 разряда с ECC.
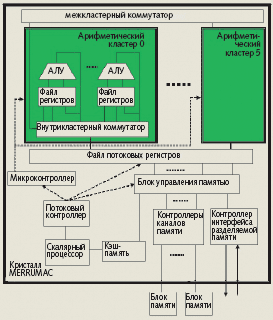
Кристалл Merrimac содержит скалярный процессор, систему управления памятью и 16 арифметических кластеров. Каждый кластер имеет четыре блока MADD (умножение с последующим сложением) над 64-разрядными операндами с плавающей точкой и ряд других функциональных блоков. Кроме того, в нем есть локальный регистровый файл из 76864-разрядных регистров и файл 64-разрядных потоковых регистров объемом 8 Kбайт. Все функциональные блоки кластера берут операнды и помещают результаты в регистры локального регистрового файла кластера или потоковые регистры. Доступ к последним выполняется через внутрикластерный коммутатор.
Скалярный процессор в совокупности с потоковым контроллером и микроконтроллером образуют потоковый процессор. Он имеет потоковую систему команд, включающую в себя обычные скалярные команды процессора с архитектурой MIPS и собственно потоковые команды. Скалярный процессор извлекает команды из своей кэш-памяти и выполняет скалярные команды. Арифметические потоковые команды направляются для исполнения под управлением микроконтроллера в арифметические кластеры.
Потоковые команды обращения к памяти исполняются под управлением потокового контроллера и системы управления памятью. Потоковый процессор имеет до 2 Гбайт локальной памяти, построенной из 16 микросхем DRAM. Пропускная способность памяти — 20 Гбайт/с. За одну потоковую команду обращения к памяти (со сборкой — разбросом данных в памяти) выполняется обмен целым потоком. Вычисления организуют так, чтобы обмен потоками с памятью скрывался за вычислениями в кластере.
Коммуникационная сеть, используемая в суперкомпьютере Merrimac, обеспечивает между всеми потоковыми процессорами быстродействие не менее 1/8 пропускной способности внутрикластерного коммутатора. Потоковый процессор изготавливается по 90-нм КМОП-технологии. Арифметический кластер имеет пиковую производительность 8 GFLOPS двойной точности на тактовой частоте 1 ГГц, что обеспечивает 128 GFLOPS двойной точности для всего потокового процессора.
Кристалл TRIPS создают техасский университет в Остине [1] совместно с IBM. Этот кристалл содержит два одинаковых процессорных ядра. Они имеют общую кэш-память второго уровня, четыре канала DDR-памяти с пропускной способностью по 2 Гбайт/с, четыре связных интерфейса для объединения кристаллов в параллельную систему (но точных сведений нет) и обеспечения ввода-вывода, а также интерфейсные блоки для контроля и диагностики. Сильно расслоенная кэш-память второго уровня состоит из 4х8 блоков, объединенных коммуникационной сетью между собой и с контроллерами памяти. Возможно (точных сведений также нет), что при организации параллельной системы из памятей, подсоединенных к разным кристаллам, образуется общая память с глобальным адресным пространством. Каждый связной интерфейс имеет два противоположно направленных канала с пропускной способностью по 2 Гбайт/с.
Процессорное ядро состоит из модуля управления G, массива 4х4 АЛУ (Е), четырех регистровых блоков R (каждый из них содержит по 32 регистра для четырех тредов), четырех блоков I кэш-памятей команд и четырех блоков D кэш-памятей данных (объемом по 16 Кбайт). Каждое АЛУ содержит буфер 64-разрядных команд, разбитый на восемь блоков по восемь команд, арифметико-логическое устройство для выполнения целочисленных операций и операций с плавающей точкой, а также три порта для приема операндов и два порта для выдачи результатов. Входные порты могут получать операнды из соседних АЛУ или регистровых блоков и кэш-памятей данных в зависимости от их соседства в решетке. Соответственно, выдача результатов из АЛУ происходит также по соседству в решетке.
АЛУ объединены в решетку 4х4, к столбцам которой подключены регистровые блоки, а к строкам — кэш-памяти команд и данных. Блок кэш-памяти команд, подключенный к строке АЛУ, используется для загрузки команд в буфер команд каждого АЛУ этой строки (путем передачи от АЛУ к АЛУ по специализированной шине). Отдельная кэш-память команд служит для выдачи команд в регистровые блоки. Исполнение этих команд в регистровых блоках инициирует потоковые вычисления в массиве 4х4 АЛУ.
Процессорное ядро исполняет гиперблоки [1], формируемые компилятором из исходной программы на языке высокого уровня, например Си, С++ или Fortran. Гиперблок может содержать до 128 команд. Компилятор разбивает гиперблок из 128 команд на восемь групп. Каждая группа, в свою очередь, образует гиперблок, предназначенный для загрузки в массив 4х4 АЛУ. Компилятор статически определяет размещение всех команд гиперблока по АЛУ массива 4х4, как показано на рисунке слева.
Гиперблок загружается во все 16 АЛУ как единое целое, затем выполняется, а результаты сохраняются в регистрах и кэш-памятях. После этого загружается следующий гиперблок, который может использовать результаты исполнения предшествующих гиперблоков в соответствии с тем, как было спланировано компилятором. В каком-то смысле гиперблок — это VLIW-команда для 16 АЛУ.
Для загрузки гиперблока модуль управления G обращается к своему «предсказателю» и получает определенный им адрес гиперблока. Далее по тегам кэш-памяти команд I, размещенным в G, осуществляется проверка того, есть ли этот гиперблок в кэш-памяти I. Если есть, то G посылает широковещательно адрес гиперблока во все блоки кэш-памяти I. Каждый блок кэш-памяти I посылает по соответствующей строке команды в буферы команд каждого АЛУ массива 4х4. Как только команда поступила в АЛУ, она может начать выполняться при получении входных операндов.
Для каждого АЛУ верхней строки массива 4х4 определены регистры, которые служат источниками операндов. Команда чтения регистра заносит операнд в соответствующее АЛУ массива. Команды гиперблока исполняются в потоковом режиме (data flow). Когда гиперблок завершается, управляющая логика сохраняет все регистры и состояние памяти, а затем удаляет гиперблок из массива 4х4 АЛУ. Каждый гиперблок выдает только одно ветвление для выбора следующего гиперблока.
Поддерживается исполнение до восьми гиперблоков одновременно. Когда G отображает гиперблок в массив 4х4 АЛУ, он также предсказывает следующий гиперблок, извлекает его и отображает. Управление переименованием регистров в гиперблоке осуществляется так, чтобы выходы предшествующего гиперблока были входами последующего.
Компилятор является основой проекта, поэтому расскажем о нем чуть подробнее. После ввода программы и построения графа потока управления (как в обычных компиляторах) он выполняет высокоуровневые преобразования графа потока управления, направленные на выделение гиперблоков — максимально больших ациклических участков [2]. Для формирования гиперблоков используются if-conversion (преобразование условных переходов в зависимости от данных), predication (введение условного выполнения команд), а также подстановка тел подпрограмм в точку вызова, агрессивная развертка циклов и другие преобразования, нацеленные на подготовку программ для VLIW-процессоров. Затем генерируется программа data flow, после чего начинается этап ее отображения на ресурсы процессорного ядра.
Компилятор формирует гиперблоки с учетом физических ограничений реализации кристалла: гиперблок не более 128 команд, не более 32 входных регистров и др. Последним этапом является распределение регистров и планирование команд, отображающее граф data flow программы на матрицу АЛУ 4х4хn, n не больше 8. Гиперблоки по 4х4 команд исполняются за один такт, а последовательность из n гиперблоков — разворачиваются во времени. Компилятор стремится расположить команды, использующие регистры, ближе к регистровым файлам, а команды, выполняющие загрузку из памяти, ближе к блокам кэш-памяти. При этом независимые команды отображаются на разные АЛУ, а команды, связанные с передачей данных, — ближе друг к другу (с целью уменьшения задержек при транзитных передачах между АЛУ).