|
О сайте Регистрация Обратная связь Реклама на сайте Публикации на сайте Карикатуры |
|
|
|
|
| Проблемы информатизации : Internet |
28.08.2007 Освоение Web 3.0
Ора Лассила, Джеймс Хендлер В статье, опубликованной в New York Times в ноябре 2006 года, репортер Джон Маркофф заявил: “Коммерческий интерес к Web 3.0 или к Semantic Web, начинает возникать только теперь” [1]. Это заявление вызвало большое замешательство по поводу отношений между Semantic Web и Паутиной как таковой, а также между Semantic Web и некоторыми аспектами концепции, известной под названием Web 2.0. Некоторые эксперты отвергали термин “Web 3.0” как чрезмерно ориентированный на бизнес; другие подозревали, что изложенные в статье концепции являются лишь частью более широкого представления о Semantic Web, а третьи чувствовали, что как ни назови, а проникновение Semantic Web в бизнес-раздел New York Times означает достижение определенной зрелости. Стандартизация Resource Description Framework (RDF) и Web Ontology Language (OWL), языков, лежащих в основе Semantic Web, и вызревание новых технологий до встраивания семантики в существующие Web-страницы и до запросов RDF к хранилищам знаний показывают, что в этой области явно происходит что-то безумно интересное. Исторический фон Semantic Web После десятилетней работы над основами Semantic Web и спустя пять лет с тех пор, как название стало популярным, сейчас самый подходящий момент, чтобы окинуть взглядом текущее положение дел и перспективы на будущее. Зародившись в виде скромной методики для машинно-интерпретируемых метаданных и пройдя через “всеохватное” представление о новой эре программного обеспечения (часто ошибочное, воспринимаемое как научная фантастика), идея Semantic Web вызрела в набор стандартов, поддерживающих “открытые” данные и взгляд на обработку информации, сфокусированный скорее на самой информации, чем на ее обработке. 
С одной из точек зрения, Semantic Web — это слияние Web-технологий и науки о представлении знаний (knowledge representation, KR), являющейся подобластью искусственного интеллекта (artificial intelligence, AI), направленное на создание и поддержание (потенциально сложных) моделей мира, которые позволяют рассуждать о себе и о связанной с ними информации. В таком качестве мы можем понять Semantic Web, опираясь на опыт, полученный при разработке и внедрении Web, а также на (возможно, несколько более болезненный) опыт внедрения технологий искусственного интеллекта. В Web мы наблюдали появление некоторых совершенно новых бизнес-моделей, которые реально работают, несмотря на то, что изначально казались неосуществимыми. К ним можно отнести модели, представленные или усовершенствованные Netscape, Amazon и eBay, Yahoo! и Google. Совместное использование информации (или “контента”, как ее часто называют в рассуждениях о Паутине) приводит к неожиданным и сказочным результатам — стоит сделать вещь доступной, и некоторые начинают использовать ее совершенно непредсказуемым образом. Феномен “длинного хвоста” (например, суммарные продажи маловостребованных товаров, вроде специализированных книг, превосходят общее количество проданных бестселлеров) бросает вызов традиционным представлениям о бизнес-моделях, но исключительно важен для новой Web-экономики. Web-сайты на самом деле существуют не в изоляции. Ссылки — вот что заставляет работать поисковые машины и наполняет силой “блогосферу”. Пройдя через эйфорию вокруг искусственного интеллекта в 80-х годах и похмелье “зимы искусственного интеллекта” 90-х, удалось выяснить, что именно не работает: отдельно стоящее “приложение искусственного интеллекта” продать нельзя. Эти технологии имеют смысл, лишь будучи встроенными в другие системы. Инструменты продавать трудно, они не особенно привлекательны для бизнеса (и уж конечно не имеют никакого смысла для венчурных капиталистов). Наконец, размышляя об искусственном интеллекте как таковом, мы замечаем, что механизмы рассуждения — это не конечная цель, а лишь средство ее достижения; важен не столько сам факт, сколько способ их использования. Со временем многие увлеклись идеями Web 2.0. Мы довольно прохладно относимся как к самому этому термину, так и вообще к нумерации версий Паутины, но признаем, что эволюционный процесс изобилует интересными явлениями. В главном, Web 2.0 представляет собой социальную революцию в использовании Web-технологий, изменение парадигмы Web от средства публикации к средству взаимодействия и участия. Однако с точки зрения Semantic Web наиболее интересны следующие технические аспекты:
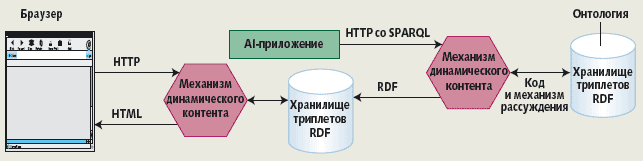
С момента выпуска стандартов RDF и OWL в 2004 году мы наблюдали множество экспериментов (и заблуждений) в поисках правильного языка представления для каждого конкретного приложения. Неудивительно, что начали появляться подмножества и расширения этих языков — наиболее заметны среди них версии RDF(S), заимствующие некоторые функции из OWL (при этом оставаясь более простыми, чем “OWL Lite”). Другие разработчики вкладывают значительные усилия в пересмотр и расширение функциональных возможностей стандарта OWL, который сейчас выходит в новой версии OWL 1.1. Поскольку большая часть текущей работы представляется на академических конференциях, появляются новые журналы, посвященные семантическим технологиям, а большинство языковых проектов выполняется в академических лабораториях и корпоративных исследовательских центрах, неудивительно, что Semantic Web воспринимается прежде всего как исследовательское направление, еще не готовое к массовому применению на практике. Тем не менее мы можем наблюдать значительную активность в разработке приложений, и, как показано в следующем разделе, она начинает приносить важные и интересные результаты. Web 3.0 Хотя сторонники Semantic Web давно наблюдали свидетельства растущего интереса, за последние несколько месяцев технологические успехи стали намного более очевидными. Это произошло в значительной степени благодаря достижению определенной зрелости языками RDF и поддерживающими их технологиями. В июле 2005 года включение компанией Oracle поддержки RDF в свой продукт Spatial 10.2g обеспечило легитимность, которой, по мнению некоторых, недоставало языку. В ходе экспериментов с базами данных RDF во многих случаях проявились их несомненные преимущества перед традиционными структурированными базами данных, особенно в отношении встраивания данных в Web. Как отмечает компания Microsoft в декабрьском выпуске Connected Services Framework 3.0 Developer Guide за 2006 год [2]: “Хранение профилей с применением RDF выгодно по двум причинам. Во-первых, RDF обеспечивает гибкую схему хранения данных, что позволяет сохранять дополнительные типы информации, о которых не было известно при первоначальной разработке схемы. Во-вторых, это помогает создавать Web-подобные отношения между данными, что нелегко сделать в обычной реляционной базе данных”. С признанием RDF назрела потребность в стандартном языке запросов для RDF, играющем ту же роль, что и SQL в реляционных данных. Протокол SPARQL и язык запросов RDF Query Language [3], сегодня проходящие стандартизацию в W3C, разработаны именно с этой целью. Директор компании-“стартапа” Radar Networks Нова Спивак отметил в своем блоге в феврале 2007 года: “В настоящее время есть огромный интерес к SPARQL, и растет число точек доступа SPARQL, возникающих в Web. Эти точки доступа по отношению к данным играют ту же роль, что и Web-сайты по отношению к документам”. Сегодня самые разные компании, большие и маленькие, развивают целый ряд направлений в Semantic Web. Например, английская компания Garlik использует технологии Semantic Web для “управления персональными данными в цифровом мире”. В частности, компания работает над тем, чтобы дать возможность пользователям обнаружить следы своего присутствия в Web и увидеть, что может раскрыть агрегирование этой информации, выставленной на обозрение через хранилище RDF. Инженер компании Yahoo Дейв Беккетт объявил в ноябре 2006 года, что сайт Yahoo Food использует OWL и RDF, а также ряд других технологий. Компания Teranode, среди прочего, исследует использование технологий Semantic Web для интеграции научных данных, особенно в области биологических наук. Joost (www.joost.com), новая платформа Internet-телевидения, ставшая героем новостей в феврале, объявив о партнерстве с Viacom, широко использует RDF. Более того, Joost собирается предоставить свою открытую внутреннюю технологию RDF некоммерческой корпорации Apache Software Foundation, расширив ее доступность для Web-разработчиков. Интересно отметить, насколько мала часть усилий, направляемая на то, что раньше казалось главной задачей Semantic Web — интеграцию корпоративных информационных активов с помощью онтологий. Нельзя сказать, что такая работа не ведется, — Oracle, IBM и несколько начинающих компаний достигли в этой области серьезных результатов, но ключевым направлением развития технологий Semantic Web является встраивание RDF и OWL в Web через имеющий первостепенное значение механизм URI. Научно-исследовательское сообщество широко эксплуатирует технологии искусственного интеллекта, которые, в частности, мотивируют развитие диалекта OWL DL, тогда как “паутинные” функции языка, иногда называемые “темной стороной” Semantic Web [4], питают пространство технологий Web 3.0. За горизонтом Web 3.0 Каким мы видим будущее Semantic Web, и в особенности, применение этих новых технологий в решении важнейших проблем, стоящих перед информационными системами? В Web 3.0 эти технологии находят плодородную почву в многоуровневых Web-приложениях, где промежуточный уровень может быть реализован с использованием хранилища триплетов RDF, которое, в частности, обеспечивает интеграцию разнородных источников данных и репозиториев. Утверждение SPARQL в качестве стандартного языка запросов для RDF позволяет многим хранилищам данных предстать в виде точек доступа SPARQL, таким образом обеспечивая гибкий обмен данными между системами. Это пролагает путь к Web-приложениям, имеющим своего рода “фрактальную” структуру с шаблонами, в которых один компонент использует другой как источник данных (например, через SPARQL) и сам выступает в роли источника данных для третьего компонента (рис. 1). Такая архитектура позволяет по-новому взглянуть на Web-сервисы и слабо связанные распределенные системы.
По существу, мы имеем все основания рассматривать технологию Semantic Web как новый подход к интероперабельности: разработчики приложений могут отложить до времени выполнения определение семантики диалога между двумя информационными системами даже после того, как системы были развернуты. Используя механизмы рассуждения для доступа к подразумеваемой информации в рамках диалога, состоящего из явных утверждений, и позволяя системам динамически развивать свои способности, обзаводясь новыми онтологиями и данными для построения рассуждений, Semantic Web дает нам возможность строить неустаревающие системы, способные действовать правильно даже в неожиданных ситуациях. Этот подход особенно полезен, когда интероперабельность является жизненно важной, например, в компьютерной среде, состоящей из множества встроенных систем. Для подключения, скажем, вашего карманного устройства к динамически изменяющейся совокупности из десятков, если не сотен, других систем, часто вам неподконтрольных (и потенциально опасных), нужны совершенно новые подходы к обеспечению интероперабельности. Мы больше не можем ожидать априорной стандартизации взаимодействия с каждой из систем, фактически, мы не можем даже представить себе все возможные сценарии таких взаимодействий. Жизнь в столь безграничном мире требует механизмов для ограничения числа вариантов при принятии решений. Например, при поиске определенного сервиса возникает желание ограничить набор кандидатов неким уместным контекстом (скажем, теми, которые находятся в вашем ближайшем окружении). Аналогичным образом, традиционные механизмы контроля доступа могут не справиться в ситуациях с неограниченным набором систем и пользователей: нужны новые механизмы принятия решений для осуществления более гибкой политики. Можно ожидать, что технологии Semantic Web позволят реализовать такого рода технологические структуры и платформы. Мы утверждаем, что понимание контекста и понимание политики — это взаимодополняющие, а не отдельные механизмы: рассматривайте политики (и их осуществление) как специфический вид контекста. В долгосрочной перспективе, когда средства описания объектов Semantic Web станут достаточно зрелыми, мы сможем использовать их выразительную мощь для описания предметов реального мира. Согласно одной из точек зрения, физические объекты станут доступны в Web в том смысле, что мы сможем представить их с помощью метаданных. Точно так же, как применение семантических технологий к проблемам интероперабельности в вездесущих вычислительных средах, описание физических объектов расширит наши возможности за пределы современной Паутины. Это мало чем отличается от утверждений, что Web-сервисы просто эксплуатируют механизмы и технологии, развитые для Web, но сами не имеют к этому никакого отношения. Усилия по развитию Semantic Web обеспечивают подход к созданию гибких, интеллектуальных информационных систем; часть из которых будут Web-приложениями, но разумеется, ими дело не ограничится. В то же время, возможности применения Web-технологий расширяются и в других направлениях. Например, консорциум W3C начал проект под названием Ubiquitous Web (“Вездесущая Паутина”), признавая выгоды от расширения Web за пределы наших ПК и ноутбуков на другие типы устройств и ситуаций. Синергетика вездесущности и семантики — захватывающая область, в которой мы ожидаем приложения значительных усилий в будущем. Около шести лет назад мы обрисовали наши представления о Semantic Web [5], включая и то, что данные, описанные способом, поддающимся машинной интерпретации, вместе со средствами для определения словарей и онтологий приведут к новым революционным Web-приложениям. Тогда в одном из отступлений мы упомянули, что не можем достоверно предсказать, каким будет “типичное приложение” Semantic Web. Мы всего лишь утверждали, что “возможности Semantic Web слишком разнообразны, чтобы размышлять о них в терминах решения одной ключевой проблемы или создания одной мощной системы. Они будут иметь такие применения, о которых мы не можем даже мечтать”. Сегодняшнее разнообразие приложений Semantic Web, от интеграции корпоративных данных до нового поколения Web-телевидения, показывает, что это было преуменьшением. Хотя многие аспекты Semantic Web все еще ждут своих исследователей, и предстоит еще много сделать, ясно, что эта технология постепенно занимает достойное место в современной Web-вселенной. Мы можем не любить термин “Web 3.0”, но мы с энтузиазмом осваиваем стоящие за ним технологии. Литература
Ора Лассила ( www.lassila.org) — научный сотрудник Исследовательского центра Nokia. Работа Лассилы в 90-х годах в области машинно-интерпретируемых метаданных для Web-ресурсов внесла вклад в появление Semantic Web. Джеймс Хендлер (www.cs.rpi.edu/~hendler) — руководитель исследовательской группы Tetherless World в Политехническом институте Ренсселера, заместитель директора научного сообщества Web Science Research Initiative, член группы W3C Semantic Web Coordination Group.Статью "28.08.2007 Освоение Web 3.0" |
||
|
|
| Copyright by MorePC - обзоры, характеристики, рейтинги мониторов, принтеров, ноутбуков, сканеров и др. | info@morepc.ru |